堆树是一种完全二叉树,完全二叉树特点:除了最后一层所有层都填满,最后一层节点从左到右排列。堆树分为两种类型:大顶堆和小顶堆。
大顶堆:每个节点的值都大于或等于其子节点的值,根节点是最大值。
小顶堆:每个节点的值都小于或等于其子节点的值,根节点是最小值。

堆的存储
由于堆是一个完全二叉树,根据完全二叉树的特点,可以使用数组存储堆树。

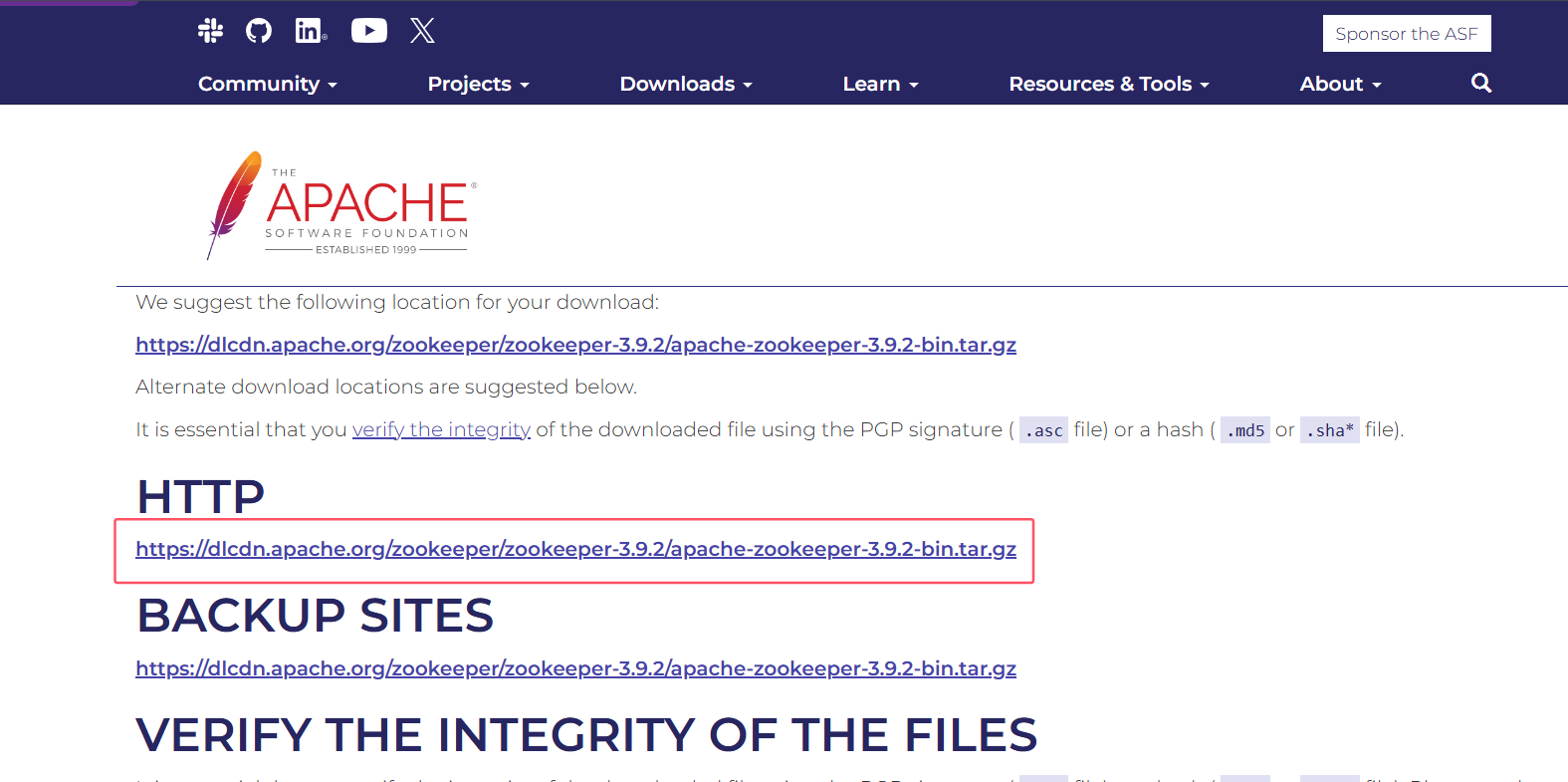
如上小顶堆。数组下标x对应的左子节点下标为x*2,右子节点元素下标为x乘2+1,其父节点下标为x/2。
如元素15其下标为3,则左子元素31的下标为6,右子元素61下标为7。父节点下标为1。
堆的构建
往堆上添加一个元素需要继续满足堆的特点,这就需要进行元素调整交换,这个过程就叫做堆化。
堆化有两种方式:
向上堆化:新插入一个节点后,比较该节点与其父节点的值,如果不符合堆的性质,则交换,继续向上堆化,直到满足堆的性质。
向下堆化:从某个节点开始,比较该节点与其子节点的值,如果不符合堆的性质(例如在最大堆中,父节点小于子节点),则交换节点和最大的子节点,继续向下堆化直到满足堆的性质。
元素的插入
这里以大顶堆构建为例来代码演示
先定义堆基本结构
int[] data; //数组存储堆
int capacity; //容量
int size;//当前堆中元素数
public MaxHeapTree(int capacity){
data = new int[capacity+1];
this.capacity = capacity;
this.size = 0;
}
向上堆化插入元素
public void insertBottom(int val){
if(size >= capacity) return;
data[++size] = val;
int current = size; //当前节点下标
int parent = current/2;//父节点下标
//判断当前节点是否大于父节点
while (parent > 0 && (data[current] > data[parent]) ){
//当前节点和父节点交换
int tmp = data[current];
data[current] = data[parent];
data[parent] = tmp;
current = parent;
parent = current/2;
}
}
向上堆化需要将新插入的元素放到堆最后。代码还是比较简单的。
插入数据测试
MaxHeapTree heap = new MaxHeapTree(10);
int[] arr = {8,6,5,9,4,27,22,55,3,88};
for (int i = 0; i < arr.length; i++) {
heap.insertBottom(arr[i]);
}
System.out.println(Arrays.toString(heap.data));
最后输出内容:[0, 88, 55, 22, 8, 27, 5, 9, 6, 3, 4] 满足大顶堆的特点。
删除堆顶元素
如果将堆顶元素取出,这里也就是取最大数。剩下的数则需要调整用来继续满足堆的特点。如果直接将堆顶元素的左右子节点提升到根节点,进行向下堆化,最后可能导致堆数不满足完全二叉树的特点。
所以这里堆顶元素删除后一般将最后一个元素拿到堆顶位置,然后进行向下堆化。这样堆化完成后的结构很顶还是完全二叉树,因为堆化过程中只进行节点的交换。
来看下具体代码
public int removeTop(){
if(size == 0) return -1;
int val = data[1];
data[1] = data[size];
heapfiyUp(1);
return val;
}
public void heapfiyUp(int index,int total){
while (true){
int max = index;
int left = index*2; //左子
int right = left +1; //右子
//找到当前节点和其两个字节点中最大的
if(left <= total && data[left] > data[max]) max = left;
if(right <= total && data[right] > data[max]) max = right;
//如果最大是当前元素,不用交换继续比较了
if(max == index) break;
//否则交换当前元素和最大元素位置
swap(index,max);
//将当前元素切换到最大元素,继续比较
index = max;
}
}
这样从堆顶元素不断取最大元素,就可以获取整个堆中topK的值。heapfiyUp方法就是从上往下进行堆化,入参就是当前要进行堆化的节点位置。
堆排序
对于堆排序只要理解了堆化的两个方法排序就变得简单了。
首先要将排序的数组进行堆化,堆化这里按上面有两种方法,向上堆化,这个是从前往后每个元素一次插入到堆中。而对于向下堆化,由于每次都是和自己子节点进行比较,由于所有的叶子节点都没有子节点,所以叶子节点不需要进行向下堆化的过程,从第一个非叶子节点进行堆化即可。由于堆数是一个完全二叉树,最后一个叶子节点是 节点数/2。所以只需要进行 节点数/2次就可以构建完成堆。
堆构建完成后,元素不是完全有序的,例如上面的例子构建完成后是[0, 88, 55, 22, 8, 27, 5, 9, 6, 3, 4]。这里只能保证一点堆顶是最大的。
排序只需要每次将堆顶元素拿出和数组最后一个元素进行交换,然后剩下的n-1个元素在进行一次向下堆化又找到了剩下的n-1个中最大的,重复上面的过程最后就完成了数组的排序。
代码如下:
public void sort(){
int n = size;//堆容量
while(n > 1){
swap(1,n);//将堆顶元素和最后一个元素交换
heapfiyUp(1,--n); //从堆顶进行向下堆化
}
}
这里省略建堆的过程。
堆通常用于实现优先队列,快速找到极值。和topK问题,topK一般建立小顶对,然后每次和堆顶元素比较即可。